Skills, MCPs, instructions personnalisées... tout le monde ajoute du contexte à ses agents. Voici pourquoi les skills sont différents, et comment l'écosystème a convergé en moins d'un an.
agentsskillsAIDX
Votre assistant IA connaît TypeScript, React, et probablement la moitié des patterns de votre codebase. Ce qu’il ne connaît pas, c’est vous : vos conventions, votre contexte, votre façon de travailler. À chaque nouvelle session, vous réexpliquez. Les skills règlent ça.
Les skills sont la réponse de l’écosystème à un problème concret : comment donner à un agent des instructions réutilisables, versionnées et contextuelles, sans les coller à la main dans chaque prompt.
Un skill, c’est un dossier qui contient tout ce dont un agent a besoin pour aborder une tâche spécifique. Le point d’entrée est un fichier SKILL.md avec un champ description dans son frontmatter, suivi du contenu du skill. On peut y ajouter des références, des templates, des scripts : tout ce qui aide.
Directory.claude/
Directoryskills/
Directoryblog-writer/
SKILL.md
Directoryreferences/
components.md
Directorycode-review/
SKILL.md
Directorytemplates/
pr-checklist.md
Voici à quoi ressemble un skill minimal :
markdown
---name: git-commitdescription: 'Execute git commit with conventional commit message analysis, intelligent staging, and message generation. Use when user asks to commit changes, create a git commit, or mentions "/commit". Supports: (1) Auto-detecting type and scope from changes, (2) Generating conventional commit messages from diff, (3) Interactive commit with optional type/scope/description overrides, (4) Intelligent file staging for logical grouping'license: MITallowed-tools: Bash---# Git Commit with Conventional Commits## OverviewCreate standardized, semantic git commits using the Conventional Commits specification. Analyze the actual diff to determine appropriate type, scope, and message.## Conventional Commit Format<type>[optional scope]: <description>[optional body][optional footer(s)]## Commit Types| Type | Purpose || ---------- | ------------------------------ || `feat` | New feature || `fix` | Bug fix || `docs` | Documentation only || `style` | Formatting/style (no logic) || `refactor` | Code refactor (no feature/fix) || `perf` | Performance improvement || `test` | Add/update tests || `build` | Build system/dependencies || `ci` | CI/config changes || `chore` | Maintenance/misc || `revert` | Revert commit |## Breaking Changes# Exclamation mark after type/scopefeat!: remove deprecated endpoint# BREAKING CHANGE footerfeat: allow config to extend other configsBREAKING CHANGE: `extends` key behavior changed## Workflow### 1. Analyze Diff```bash# If files are staged, use staged diffgit diff --staged# If nothing staged, use working tree diffgit diff# Also check statusgit status --porcelain```### 2. Stage Files (if needed)If nothing is staged or you want to group changes differently:```bash# Stage specific filesgit add path/to/file1 path/to/file2# Stage by patterngit add *.test.*git add src/components/*# Interactive staginggit add -p```**Never commit secrets** (.env, credentials.json, private keys).### 3. Generate Commit MessageAnalyze the diff to determine:- **Type**: What kind of change is this?- **Scope**: What area/module is affected?- **Description**: One-line summary of what changed (present tense, imperative mood, less than 72 characters)### 4. Execute Commit```bash# Single linegit commit -m "<type>[scope]: <description>"# Multi-line with body/footergit commit -m "$(cat <<'EOF'<type>[scope]: <description><optional body><optional footer>EOF)"```## Best Practices- One logical change per commit- Present tense: "add" not "added"- Imperative mood: "fix bug" not "fixes bug"- Reference issues: `Closes #123`, `Refs #456`- Keep description under 72 characters## Git Safety Protocol- NEVER update git config- NEVER run destructive commands (--force, hard reset) without explicit request- NEVER skip hooks (--no-verify) unless user asks- NEVER force push to main/master- If commit fails due to hooks, fix and create NEW commit (don't amend)
Deux modes d’invocation :
Explicite : /blog-writer, /code-review. Vous appelez le skill par son nom.
Automatique : l’agent charge toutes les descriptions de skills au démarrage de la session, puis les fait correspondre sémantiquement à votre message.
C’est pourquoi le champ description est la partie la plus importante d’un skill. C’est lui qui détermine si l’agent le charge ou l’ignore.
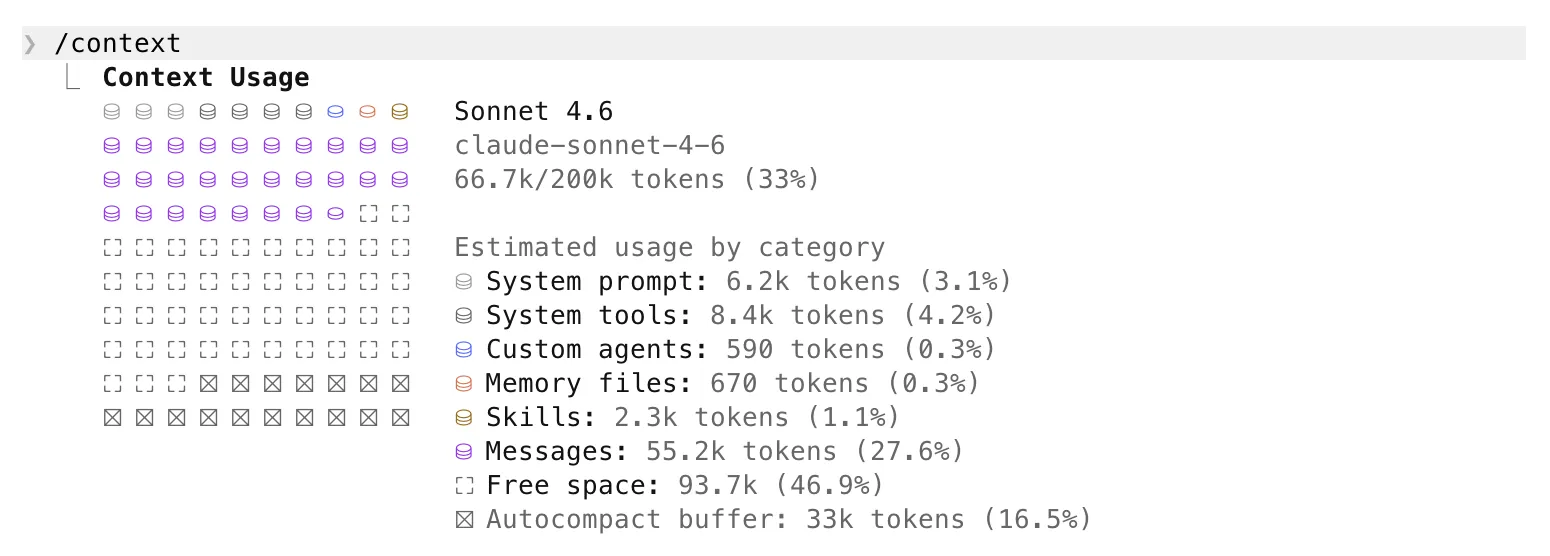
C’est là que les skills se distinguent des outils et MCPs sur la gestion du contexte. Un MCP charge ses schémas d’outils au démarrage, qu’il soit utilisé ou non. Un skill ne charge que sa description au démarrage, quelques dizaines de tokens, et son contenu complet uniquement si déclenché. Avec 20 skills installés, la surcharge reste négligeable.
38 skills disponibles, 2,3k tokens utilisés. Les descriptions sont légères ; le contenu complet ne se charge que quand l'agent en a besoin.
En moins d’un an, tous les assistants de dev majeurs ont adopté le même concept et le même format : un dossier avec un SKILL.md, un frontmatter name + description, le reste en markdown. Claude Code, Copilot, Gemini CLI, Cursor, opencode.ai, Codex : même structure, même logique.
La seule vraie différence, c’est le chemin. .agents/skills/ est en train de devenir le standard cross-outils : Copilot, Gemini, Cursor, Opencode et Codex le lisent nativement. Seul Claude Code continue à faire cavalier seul avec .claude/skills/, mais un symlink suffit pour tout aligner.
Vercel a lancé skills.sh, un registre open-source de skills communautaires avec une CLI pour les installer :
bash
npx skills add vercel-labs/agent-skills
La commande installe le skill dans .agents/skills/ (le chemin canonique) et propose deux modes : des symlinks vers .claude/skills/, .cursor/skills/, etc. (recommandé, source de vérité unique) ou des copies directes dans le dossier de chaque outil (utile si vous voulez des versions divergentes par assistant).
Les trois existent déjà. La question est légitime.
mermaid
Trois primitives distinctes. Les skills sont au milieu : pas toujours chargés, pas de simples capacités.
Les instructions système (CLAUDE.md, .cursorrules…) sont toujours chargées, à chaque session, qu’elles soient pertinentes ou non. C’est bien pour les conventions globales du projet. Mais si vous avez 10 workflows différents, vous ne pouvez pas tout mettre dans CLAUDE.md sans noyer l’agent dans du contexte dont il n’a pas besoin les trois quarts du temps.
Les MCPs donnent des capacités à l’agent : interroger une base de données, appeler une API, accéder à des fichiers distants. Ils répondent à “que peut faire l’agent ?”. Les skills répondent à “comment doit l’agent aborder ça ?”. Ce n’est pas la même question. Un MCP de recherche web ne sait pas quelles sources vous privilégiez, ni dans quel format vous voulez les résultats. Un skill le précise. Et un skill peut décrire comment et quand utiliser un outil ou MCP spécifique directement dans son contenu.
Les outils (function calling) suivent la même logique que les MCPs : des capacités d’action. Un outil peut écrire un fichier. Il ne connaît pas vos conventions de nommage, ni comment vous structurez vos composants.
Vous pourriez charger ce contexte manuellement avant chaque tâche. Beaucoup de gens le font, avec des extraits de prompt collés dans leur éditeur. Ça marche, jusqu’à ce que vous oubliiez, que vous changiez de machine, ou que vous onboardiez quelqu’un. Les skills rendent le chargement automatique, versionné et partageable. Vous arrêtez de vous réexpliquer.
Les skills de projet vivent dans .agents/skills/ ou .claude/skills/ à la racine du repo. Committez-les : ce sont des artefacts d’équipe, au même titre que les linters ou les configs CI. N’importe quel dev qui clone le repo obtient les mêmes workflows.
Les skills personnels vont dans ~/.claude/skills/ ou ~/.agents/skills/. Vos conventions personnelles, raccourcis, particularités. Pas dans le repo.
settings.local.json reste en local. Il contient votre configuration personnelle de l’agent : permissions, préférences, overrides. Il n’est pas fait pour être partagé.
Ce n’est pas théorique. Le vecteur d’attaque est simple : vous installez un skill “pratique” trouvé en ligne, il contient des instructions cachées dans le contenu, votre agent les exécute sans que vous le remarquiez. Même risque que copier un script shell sans le lire.
La règle est la même qu’avec n’importe quel code tiers : faites confiance aux sources que vous connaissez, vérifiez le reste.
Les skills ne remplacent pas vos outils, MCPs ou instructions système. Ils comblent ce qui manquait entre les trois : une couche d’expertise procédurale, chargée à la demande, versionnée avec votre code, partageable entre une équipe.
Si vous utilisez Claude Code, Cursor, Copilot ou Gemini CLI aujourd’hui, vous pouvez créer votre premier skill en 10 minutes. Un fichier SKILL.md, une description bien écrite, et votre prochain workflow répétitif devient une commande.
La prochaine question, c’est comment organiser et partager les skills quand la collection grandit. C’est ce dont mon prochain article parlera, en couvrant un outil que je suis en train de construire : SkillForge. 👀